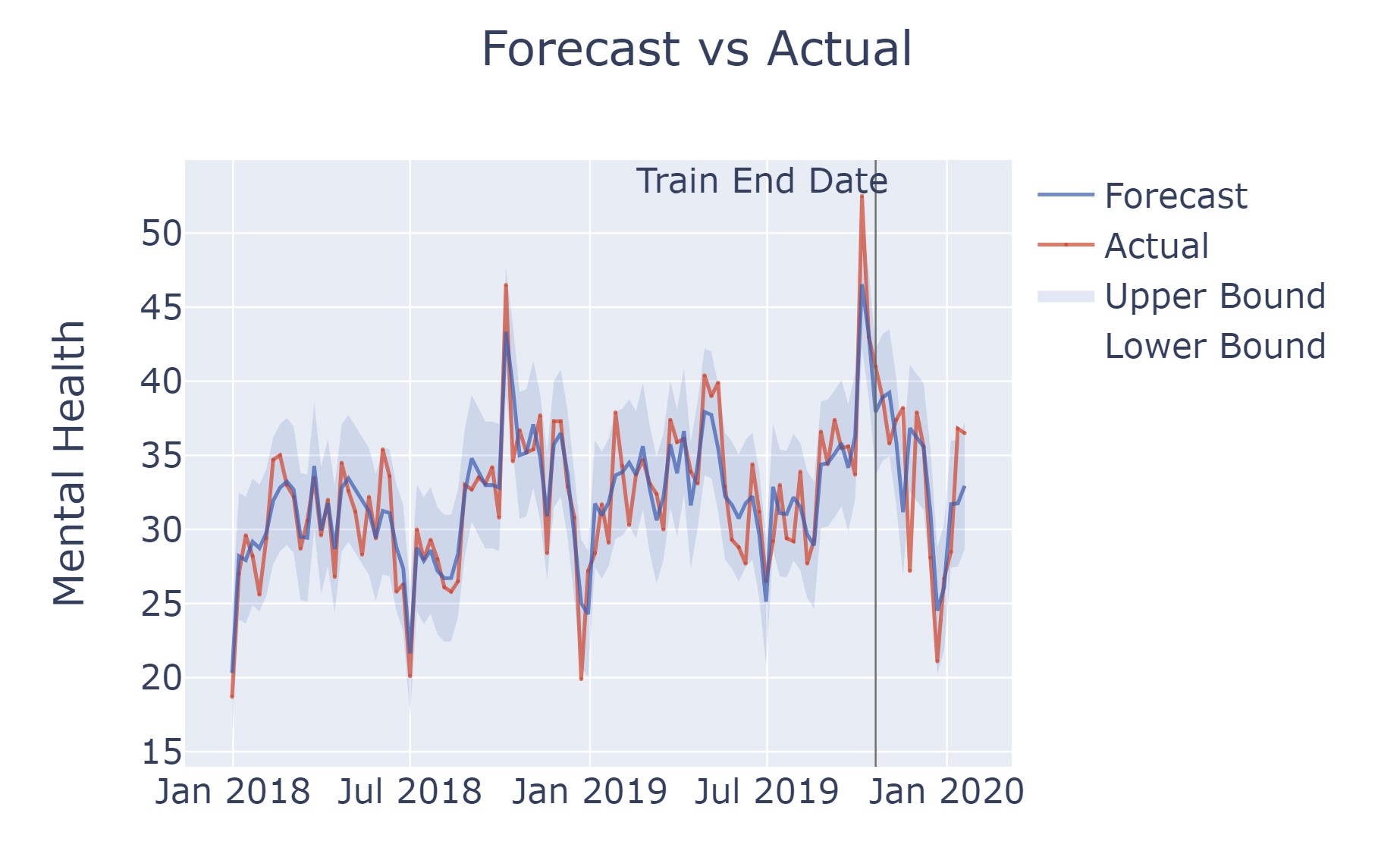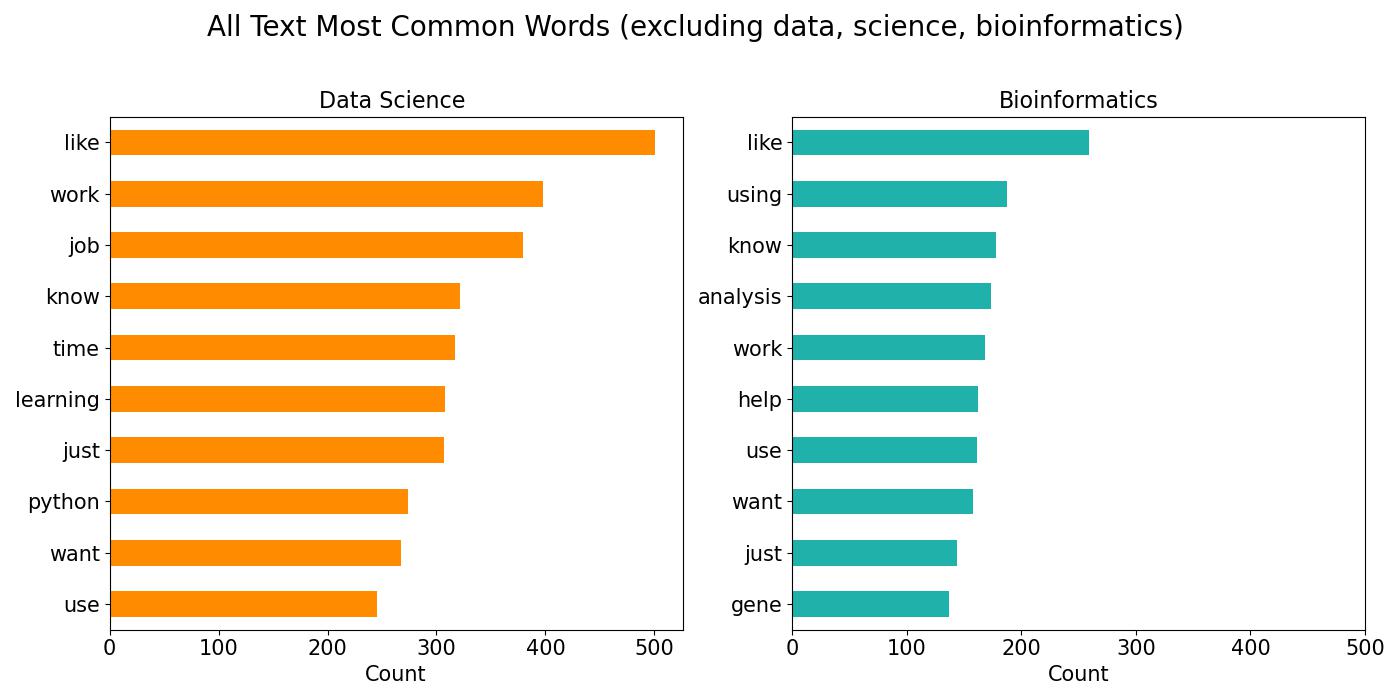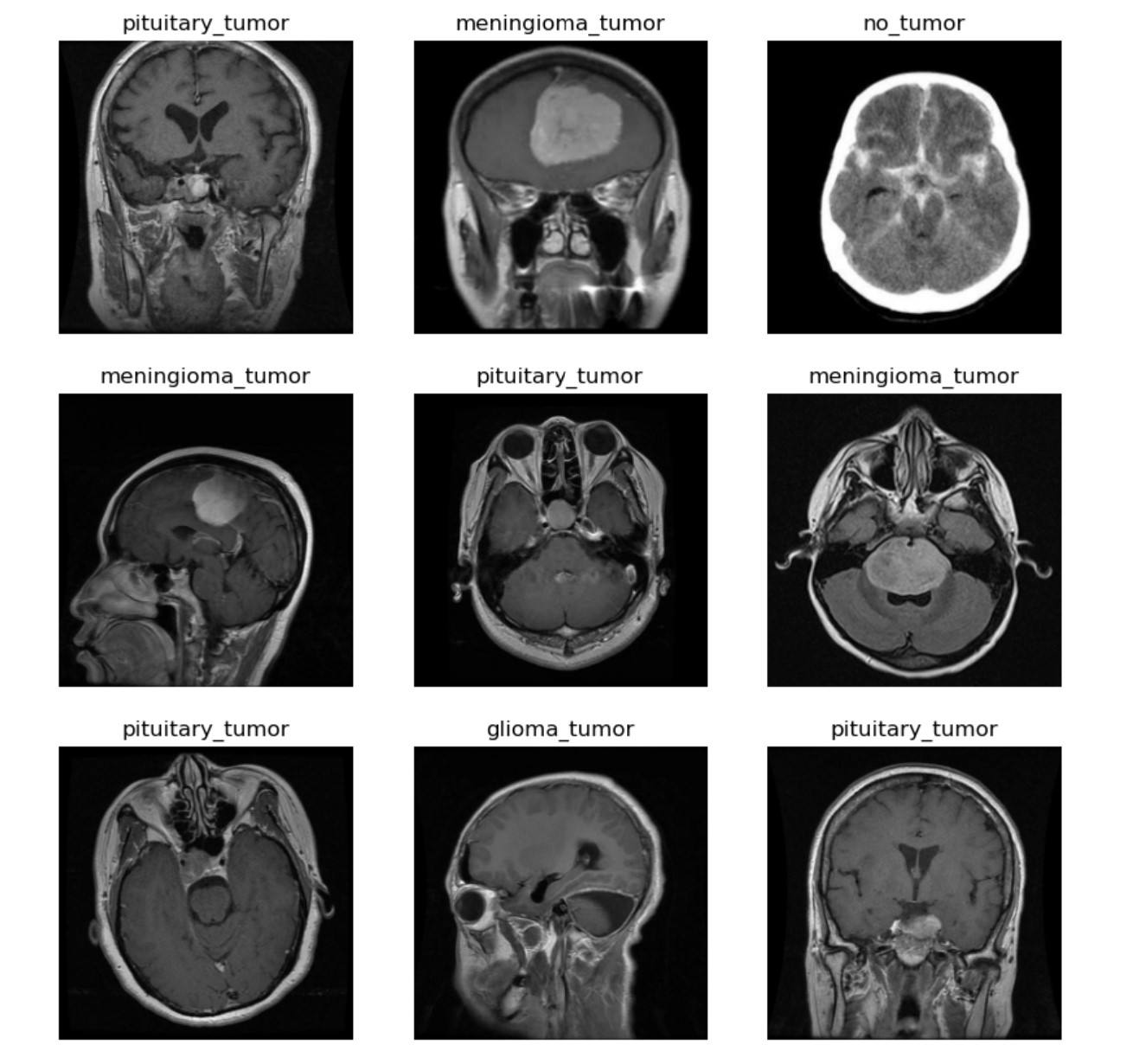
MRI disease classification
Throughout this project, I constructed four distinct models employing Convolutional Neural Networks (CNNs) to classify Brain MRI scans with the intention of identifying two particular diseases: Alzheimer's disease and brain tumors. The classification will depend on disease severity and tumor type. My most successful models utilized ResNet50, EfficientNetV2S, and augmented data through the Albumentations library. By combining these models, I developed a Streamlit application enabling users to classify individual input images. Upon uploading an image, the application displays it and predicts the corresponding class label and probability utilizing pre-trained models.